Le Machine Learning est une technique de programmation informatique parmi les plus recherchées dans le secteur de la technologie. Les géants du secteur Tech comme Google, Microsoft et Amazon utilisent des algorithmes de Machine Learning pour améliorer l’expérience client et augmenter les revenus. Nous allons vous exposer dans cet article tout ce que vous devez savoir sur le Machine Learning.
Définition
Le Machine Learning est une branche de l’intelligence artificielle (IA) qui donne aux ordinateurs la capacité d’apprendre par eux-mêmes sans programmation explicite. Comme le font les humains, en améliorant leur mode d’apprentissage et leurs connaissances de façon autonome sur la durée. Les modèles du Machine Learning sont créés en obtenant des échantillons de données puis en entraînant le modèle sur ces donnée et l’utiliser pour prendre des décisions ou faire des prédictions sur des données nouvelles et inconnues. L’objectif ultime serait que les ordinateurs agissent et réagissent sans être explicitement programmés pour ces actions et réactions.
Histoire
Le Machine Learning n’est pas une nouvelle technologie. Le premier réseau neuronal artificiel, appelé « Perceptron », a été inventé en 1958 par le psychologue américain Frank Rosenblatt.
Au départ, Perceptron devait être une machine, et non un algorithme. En 1960, il a été utilisé pour le développement de la machine de reconnaissance d’images « Mark 1 Perceptron » qui été le premier ordinateur à utiliser des réseaux neuronaux artificiels (ANN) pour simuler la réflexion humaine et apprendre par essais et erreurs.
Ensuite, la puissance de traitement des ordinateurs a été développée pour prendre en charge des des puces, notamment les GPU et les TPU (Tensor Processing Units), spécialisées dans l’entraînement des réseaux neuronaux.
Enfin, les logiciels comme Apache MXNet ou TensorFlow ont été créés pour permettre aux développeurs de construire plus facilement des applications utilisant ces nouvelles techniques et composants matériels.
Les catégories du Machine Learning
Le Machine Learning peut être classé en trois grandes catégories :
1- Machine Learning supervisé
Le Machine Learning supervisé est une technologie qui consiste à présenter à l’ordinateur les données d’entrées et les sorties souhaitées, et l’ordinateur recherche des solutions pour obtenir ces sorties en fonction de ces entrées. Le but est que l’ordinateur apprenne la règle générale qui mappe les entrées et les sorties. On parle de « modélisation prédictive ». L’algorithme essaie de développer une fonction qui prédit avec précision la sortie à partir des variables d’entrée. Le Machine Learning supervisé peut se subdiviser en deux types :
- Classification : la variable de sortie est une catégorie.
- Régression : la variable de sortie est une valeur spécifique.

Les principaux algorithmes du Machine Learning supervisé sont les suivants : forêts aléatoires, arbres de décision, algorithme K-NN (k-Nearest Neighbors), régression linéaire, algorithme de Naïve Bayes, machine à vecteurs de support (SVM), régression logistique et boosting de gradient.
2- Machine Learning non supervisé
Dans le cadre du Machine Learning non supervisé, l’algorithme détermine lui-même la structure de l’entrée (aucune étiquette n’est appliquée à l’algorithme). Cette approche est appelée « feature learning » (apprentissage des caractéristiques). Il existe deux types de Machine Learning non supervisé :
- Clustering : l’objectif consiste à trouver des regroupements dans les données.
- Association : l’objectif consiste à identifier les règles qui permettront de définir de grands groupes de données.

Les principaux algorithmes du Machine Learning non supervisé sont les suivants : K-Means, clustering/regroupement hiérarchique et réduction de la dimensionnalité.
3. Machine Learning par renforcement
Dans le Machine Learning par renforcement, le programme informatique interagit avec un environnement dynamique dans lequel il doit atteindre un certain but et apprendre à identifier le comportement le plus efficace dans le contexte considéré. L’apprentissage par renforcement utilise des récompenses et des punitions comme signaux de retour, permettant à un agent (machine) d’apprendre de ses expériences sans être explicitement programmé sur ce qu’il doit faire ensuite – l’agent « apprendra de ses erreurs ». Il existe deux types de Machine Learning par renforcement :
- Monte Carlo : le programme reçoit ses récompenses à la fin de l’état « terminal ».
- Machine Learning par différence temporelle (TD) : les récompenses sont évaluées et accordées à chaque étape.
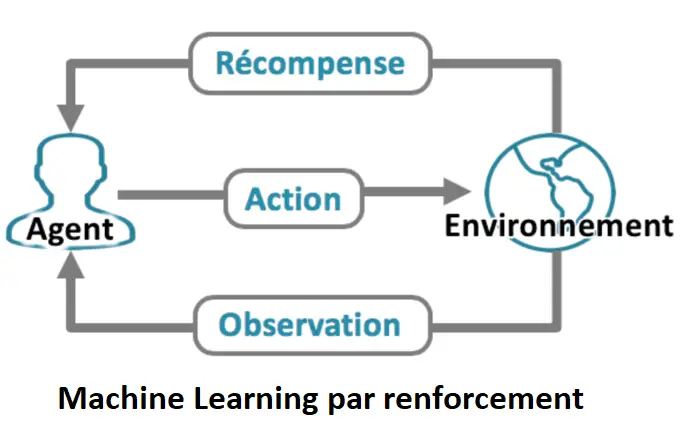
Les principaux algorithmes du Machine Learning par renforcement sont les suivants : Q-learning, Deep Q Network (DQN) et SARSA (State-Action-Reward-State-Action).
Les types d’algorithmes du Machine Learning
Le Machine Learning utilise de nombreux types d’algorithmes. L’algorithme utilisé dépend de la complexité et du type de problème à résoudre ou d’action à exécuter. Voici quelques exemples d’algorithmes du Machine Learning :
Arbre de décision
Un arbre de décision est un type d’algorithme qui établis l’arborescence de divers résultats qui peuvent ou ne peuvent pas se produire, et suit chaque événement jusqu’à sa conclusion naturelle tout en calculant toutes les probabilités des événements pouvant se produire.
Exemple : Les compagnies pharmaceutiques peuvent utiliser des algorithmes d’arbre de décision pendant leurs tests pour calculer la probabilité des effets secondaires et le coût moyen du traitement.
Forêts aléatoires
La forêt aléatoire est un algorithme qui construit plusieurs arbres de classification et de régression (CART, Classification and Regression Tree), chaque arbre étant associé à différents scénarios et différentes variables initiales. L’algorithme est randomisé, ce qui n’est pas le cas des données. Ce type d’algorithme est utilisé pour la modélisation prédictive de classification et de régression.
Algorithmes K-Means
Les K-Means sont des algorithmes de machine learning sans supervision qui divisent et classent un ensemble de points de données non affectés d’un label en un groupe appelé « cluster ». Chaque itération de l’algorithme assigne chaque point à un groupe présentant des caractéristiques similaires. Les points de données peuvent être suivis dans le temps pour détecter les changements qui se produisent dans les clusters.
Exemples d’utilisation du machine learning
Netflix utilise le machine learning pour classer les films et les émissions de télévision en fonction de vos préférences. Plus vous regardez Netflix, plus il est en mesure de vous recommander de nouveaux contenus en fonction de ce que vous avez déjà regardé.
Amazon utilise le machine learning pour suggérer automatiquement des produits connexes lorsque vous naviguez sur son site Web ou son application. Si vous achetez un livre sur la cuisine, Amazon vous en suggérera d’autres qui pourraient vous plaire en fonction de vos achats et de vos recherches antérieures.
Une voiture autonome est équipée de plusieurs caméras, plusieurs radars et capteurs. Ces différents équipements assurent les fonctions suivantes :
- Utiliser le GPS pour déterminer l’emplacement de la voiture en permanence et avec précision
- Analyser la section de route située en avant de la voiture
- Détecter les objets mobiles ou fixes situés sur l’arrière ou les côtés de la voiture
Ces informations sont traitées en permanence par un ordinateur central installé dans la voiture. Cet ordinateur collecte et analyse en permanence des volumes considérables de données et les classe de la même manière que les réseaux neuronaux d’un cerveau humain. Pour guider la voiture dans son environnement, l’ordinateur prend des milliers de décisions par seconde en fonction de probabilités mathématiques et de ses observations : comment tourner le volant, quand freiner, accélérer, changer les vitesses, etc.


